This paper, part of the IS2024 conference proceedings, addresses the growing importance of validating Large Language Models (LLMs) in the medical domain, focusing on prompt engineering. This work proposes a structured methodology using combinatorial testing to systematically evaluate LLM responses to medical queries. The approach generates test cases by combining sets of symptoms with various prompt components, utilizing pairwise combinatorial testing to efficiently cover a wide range of prompt variations without causing a combinatorial explosion.
The proposed validation pipeline implements a semi-automated scoring system based on a “golden model” that provides diagnoses curated by medical professionals. The methodology aims to reduce costs and increase efficiency compared to testing all possible combinations of prompt parameters, which is particularly crucial when evaluating LLMs on large medical corpora. The approach was demonstrated using GPT-4o as the system under test and NetDoktor’s Symptom-Checker as the golden model.
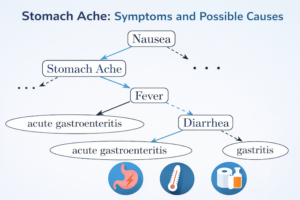
In a preliminary study, significant differences in output for prompt variations given the same set of symptoms were found. Out of 24 test cases generated for an exemplary set of symptoms, only one achieved a full overlap with the golden model when using GPT-4o. This finding underscores the dependence on well-formulated prompts and the need for thorough testing strategies, especially in critical domains like medicine. The study highlights the potential of combinatorial testing in prompt engineering and emphasizes the importance of rigorous validation methodologies for LLMs in healthcare applications.