Paper: Dobreva, J., Simjanoska Misheva, M., Mishev, K., Trajanov, D., & Mishkovski, I. (2025). A Unified Framework for Alzheimer’s Disease Knowledge Graphs: Architectures, Principles, and Clinical Translation. Brain Sciences, 15(5), 523. https://doi.org/10.3390/brainsci15050523
Alzheimer’s disease remains one of the most complex and pressing neurological challenges of our time. Scientists across disciplines continue to uncover critical clues – from genomic variations and neuroimaging biomarkers to clinical narratives and drug responses. However, the sheer diversity and volume of this data often lead to fragmentation, impeding the ability to form a coherent understanding of the disease’s underlying mechanisms.
The Challenge: Fragmented Insights in a Data-Rich Environment
Biomedical data relevant to Alzheimer’s disease is vast and multifaceted. Repositories such as PubMed, STRING, DrugBank, ADNI, and OASIS contain valuable research articles, protein interaction maps, drug mechanisms, and imaging datasets. Despite their significance, these resources often exist in isolated silos, disconnected in form and semantics.
This lack of integration hinders researchers’ ability to discern cross-domain relationships, for instance, how a genetic mutation may influence a brain structure visible in MRI, and how this may relate to clinical symptoms or therapeutic responses. Addressing this challenge requires not just more data, but a smarter way to organize, interpret, and use it.
The Solution: A Structured Approach to Knowledge Graph Development
Knowledge Graphs (KGs) offer a promising paradigm by providing structured, semantically rich representations of biomedical concepts and their interrelations. However, their potential has been underutilized in Alzheimer’s research due to the absence of unified design principles that accommodate both data diversity and application demands.
Our recent publication, A Unified Framework for Alzheimer’s Disease Knowledge Graphs: Architectures, Principles, and Clinical Translation, introduces AD-KG 2.0 – a comprehensive blueprint designed to guide the systematic construction and deployment of Alzheimer’s-specific KGs. This framework integrates best practices across data ingestion, integration, computation, and application, offering a strategic roadmap for researchers and developers alike.
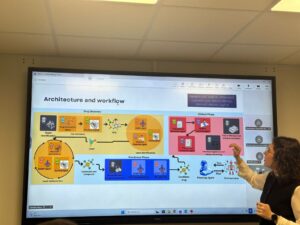
The AD-KG 2.0 Architecture: Four Foundational Layers
The following figure outlines the pipeline architecture, which is modular and adaptive to varied research settings.

Layer 1: Data Ingestion – Structured Capture of Heterogeneous Clues
This layer emphasizes the systematic extraction and transformation of Alzheimer’s-relevant information:
- Scientific literature: Utilizing LLM-enhanced methods to extract entities and relationships with high precision.
- Structured databases: Integrating resources like STRING, DrugBank, and AlzKB using standardized APIs and protocols.
- Neuroimaging datasets: Applying pipelines to convert imaging features into graph-compatible formats.
- Clinical and omics data: Developing robust extractors to handle variability in patient and molecular data while preserving semantic integrity.
Layer 2: Knowledge Integration – Creating Semantic Coherence
This layer aligns terminologies and defines relationships:
- Terminology harmonization: Combining UMLS, ADO, and context-aware models like BioBERT to bridge semantic gaps across datasets.
- Relationship taxonomy: Encoding biological and clinical interactions (e.g., gene–protein–phenotype links).
- Temporal modeling: Capturing disease dynamics over time.
- Uncertainty management: Assigning confidence scores to relationships to reflect evidence variability.
The following figure provides a detailed representation of the harmonization process across ontology tiers, embeddings, and schema normalization.

Layer 3: Computational Layer – Enabling Intelligent Inference
This analytical layer supports several KG-powered tasks:
- Link prediction & embeddings: Using models like ComplEx to infer novel biological associations.
- Multimodal GNNs: Integrating clinical, imaging, and genetic data streams to improve classification performance.
- Explainable AI models: Prioritizing models to ensure clinicians understand AI-derived recommendations.
- Comorbidity-aware networks: Adapting models to account for complex patient profiles, especially those with co-existing conditions.
Layer 4: Application Layer – Translating Knowledge into Practice
This final layer supports real-world utility:
- Drug repurposing: Leveraging KG-DTI for systematic identification of potential Alzheimer’s therapies.
- Patient stratification: Applying unsupervised learning to KG features to inform precision medicine strategies.
- Clinical decision support: Deploying tools based on frameworks like DALK for improved diagnostic and treatment recommendations.
- Hypothesis generation: Utilizing causal inference to identify novel research directions.
What Sets AD-KG 2.0 Apart?
Rather than presenting a single KG, AD-KG 2.0 formalizes a methodological synthesis:
- Systematic Decision Framework: A decision tree for method selection based on data availability and application goals as depicted in the following figure.
- Dual-Constraint Optimization: Method choices are aligned with both data characteristics and intended outputs.
- Semantic Alignment Layer: A dedicated step for harmonizing terminology across domains.
- Context-Sensitive Method Selection: Encouraging flexible methodology based on scenario-specific constraints.

Demonstrated Benefits from the Field
Empirical studies cited in our paper support the effectiveness of AD-KG 2.0-aligned methodologies:
- Improved entity extraction: LLM-enhanced NLP achieves up to 27% higher entity coverage.
- Better classification: Multimodal GNNs improve performance by over 7% in some settings.
- Higher clinical adoption: Explainable models facilitate trust and usability among healthcare professionals.
- More effective discovery: Advanced embeddings yield superior hit rates in drug-target predictions.
From Concept to Clinic: Translational Pathways
AD-KG 2.0 also addresses critical challenges in clinical translation:
- Data privacy: Proposes federated learning as a strategy to protect sensitive health data.
- Workflow integration: Advocates for user-centered design and natural language interfaces.
- Regulatory alignment: Emphasizes the need for standardized evaluation protocols.
- Trust-building: Prioritizes interpretability to enhance clinician engagement.
Beyond Alzheimer’s: Generalizing the Framework
While designed for Alzheimer’s disease, the framework’s modular structure makes it adaptable to other neurodegenerative conditions. By replacing disease-specific elements in the ingestion and application layers, the core principles and methodologies can support KG development in domains such as Parkinson’s disease and ALS.
Conclusion: Toward a Connected and Guided Future
AD-KG 2.0 offers the research community a robust, evidence-based guide to building knowledge graphs that not only integrate Alzheimer’s data more effectively but also support actionable, translational insights. By bridging fragmentation and enabling adaptive decision-making, it supports:
- More rapid drug discovery.
- Earlier and more accurate diagnosis.
- Enhanced patient stratification for personalized care.
- Generation of novel research hypotheses.
We invite researchers, developers, and clinicians to explore the full publication for a detailed description of the framework and its foundational principles.
Read the full paper here:
A Unified Framework for Alzheimer’s Disease Knowledge Graphs: Architectures, Principles, and Clinical Translation
https://www.mdpi.com/2076-3425/15/5/523
This research was conducted by a multidisciplinary team at the Faculty of Computer Science and Engineering within the Ss. Cyril and Methodius University, Skopje, and funded by the European Union under Horizon Europe (project ChatMED, grant agreement ID: 101159214).