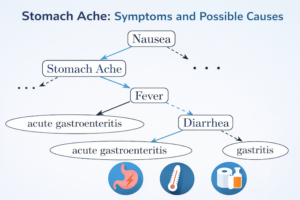
The study, part of the IS2024 conference proceedings, evaluated ChatGPT’s performance in medical diagnostic tasks. ChatGPT was assessed by comparing medical diagnoses to a professional medical expert system, NetDoktor’s Symptom-Checker.
To achieve this, a semi-automated validation procedure was developed, which uses NetDoktor as a golden model to generate sets of symptoms and corresponding diagnoses. These symptom descriptions were then used as prompts for ChatGPT, powered by GPT-4o. The study compared ChatGPT’s diagnoses with those from NetDoktor using an overlap score, considering semantic equivalences in medical terminology.
The key findings revealed that ChatGPT’s diagnoses only partially matched those from the expert system. The highest overlap with NetDoktor’s diagnoses was achieved using a simple prompt in German, with an average overlap of 31%. The study also found that neither prompting in English, nor asking for a specific number of “most likely” diagnoses did improve the quality of ChatGPT’s output. These results highlight the potential risks of relying solely on AI for medical diagnoses and underscore the importance of consulting healthcare professionals. It is planned to expand this study with larger-scale experiments and further analysis of prompt engineering’s impact on diagnosis retrieval.